优化的前置知识
从资源视角出发来对一台服务器进行审视的话,CPU、内存、磁盘与网络是后端服务最需要关注的四种资源类型。
对于计算密集型的程序来说,优化的主要精力会放在 CPU 上,要知道 CPU 基本的流水线概念,知道怎么样在使用少的 CPU 资源的情况下,达到相同的计算目标。
对于 IO 密集型的程序(后端服务一般都是 IO 密集型)来说,优化可以是降低程序的服务延迟,也可以是提升系统整体的吞吐量。
IO 密集型应用主要与磁盘、内存、网络打交道。因此我们需要知道一些基本的与磁盘、内存、网络相关的基本数据与常见概念:
- 要了解内存的多级存储结构:L1,L2,L3,主存。还要知道这些不同层级的存储操作时的大致延迟:go内存分配
- 要知道基本的文件系统读写 syscall,批量 syscall,数据同步 syscall。
- 要熟悉项目中使用的网络协议,至少要对 TCP, HTTP 有所了解。
优化是与业务场景相关的
不同的业务场景优化的侧重也是不同的。
对于大多数无状态业务模块来说,内存一般不是瓶颈,所以业务 API 的优化主要聚焦于延迟和吞吐。对于网关类的应用,因为有海量的连接,除了延迟和吞吐,内存占用可能就会成为一个关注的重点。对于存储类应用,内存是个逃不掉的瓶颈点。
在关注一些性能优化文章时,应特别留意作者的业务场景。场景的侧重可能会让某些人去选择使用更为 hack 的手段进行优化,而 hack 往往也就意味着 bug。例如用Golang的unsafe-convert转成unsafe.Pointer去解决cpu的性能瓶颈的时候,要必须清楚转换后的类型是什么,不然会很容易出错死掉。
优化的工作流程
对于一个典型的 API 应用来说,优化工作基本遵从下面的工作流:
-
建立评估指标,例如固定 QPS 压力下的延迟或内存占用,或模块在满足 SLA 前提下的极限 QPS
-
通过自研、开源压测工具进行压测,直到模块无法满足预设性能要求:如大量超时,QPS 不达预期,OOM
-
通过内置 profile 工具寻找性能瓶颈
-
本地 benchmark 证明优化效果
-
how to benchmark
go test -bench cpu profile
go test -bench memory profile
-
-
集成 patch 到业务模块,回到 2
common performance cases(常见的性能优化)
- blocking
- High CPU usage
- High Memory usage
Blocking
锁冲突严重,导致吞吐量瓶颈
如:
map中的sync.Mutex
Broccli框架里面的prometheus自定义Export,为了用prometheus做到全链路监听,所以定义了一系列的prometheusExport,并用享元模式共享到了每个容器中。
在Broccli早前的版本中,mutex没用好,导致blocking,Goroutine有大量的堆积
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
type PrometheusClient struct {
clients map[string]*PromClient
mutex *sync.Mutex
}
var HTTPCLIENT = "httpClientProm"
func Access(ng engine.Engine) gin.HandlerFunc {
...
ng.GetContainer().GetPrometheusMap().mutex.Lock()
prom, ok := ng.GetContainer().GetPrometheusMap()[HTTPCLIENT]
ng.GetContainer().GetPrometheusMap().mutex.Unlock()
if ok {
go func (){
prom.HTTPServer.Incr(c.Request.URL.Path, strconv.Itoa(int(baseRsp.Errcode)))
}
}
}
这个锁的设置理念是用来在终止prometheus收集器到时候value对象置空,sync.Mutex和sync.RWMutex没用好,导致Blocking
通过压测可以比较快地发现问题,达到一定 QPS 压力时,会有大量的 Goroutine 堆积,通过pprof看到下面有 18910 个 G 堆积在抢锁代码上:

真实问题实际上本质都是并发场景下的 lock contention 问题,全局锁是高并发场景下的性能杀手,一旦大量的 Goroutine 阻塞在锁上,会导致系统的延迟飚升,直至接口超时。
解决方法:把锁的粒度、操作、级别等放开,如上述例子,把sync.Mutex换成sync.RWMutex就可以解决问题。
另一个例子:
UDP中的写锁
在做运营中台的过程中,metrics 上报 client 都是基于 udp 的,简单粗暴,就是一个 client,用户传什么就写什么,最后源码会走到:
1
2
3
4
5
6
func (c *UDPConn) WriteToUDP(b []byte, addr *UDPAddr) (int, error) {
---------- 刨去无用细节
n, err := c.writeTo(b, addr)
---------- 刨去无用细节
return n, err
}
调用的是:
1
2
3
4
func (c *UDPConn) writeTo(b []byte, addr *UDPAddr) (int, error) {
---------- 刨去无用细节
return c.fd.writeTo(b, sa)
}
然后:
1
2
3
4
5
func (fd *netFD) writeTo(p []byte, sa syscall.Sockaddr) (n int, err error) {
n, err = fd.pfd.WriteTo(p, sa)
runtime.KeepAlive(fd)
return n, wrapSyscallError("sendto", err)
}
然后是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
func (fd *FD) WriteTo(p []byte, sa syscall.Sockaddr) (int, error) {
if err := fd.writeLock(); err != nil { =========> 重点在这里
return 0, err
}
defer fd.writeUnlock()
for {
err := syscall.Sendto(fd.Sysfd, p, 0, sa)
if err == syscall.EAGAIN && fd.pd.pollable() {
if err = fd.pd.waitWrite(fd.isFile); err == nil {
continue
}
}
if err != nil {
return 0, err
}
return len(p), nil
}
}
本质上,选用UDP的原因简单,快、可接受丢包。但在fd网络操作上套了一把大的写锁,同样在高并发场景下会导致大量的锁冲突,进而导致大量的 Goroutine 堆积和接口延迟。
解决方法:multiple clients 直接增加客户端,有效的降低锁的冲突
锁优化的思路
一个“拆”和一个“缩”
- 拆:将锁粒度进行拆分,比如全局锁,我能不能把锁粒度拆分为连接粒度的锁;如果是连接粒度的锁,那我能不能拆分为请求粒度的锁;在 logger fd 或 net fd 上加的锁不太好拆,那么我们增加一些客户端,比如从 1-> 100,降低锁的冲突是不是就可以了。
- 缩:缩小锁的临界区,比如业务允许的前提下,可以把 syscall 移到锁外面;比如我们只是想要锁 map,但是却不小心锁了连接读写的逻辑,需要用读写锁的地方用了互斥锁等,或许简单地用 sync.Map 来代替 map Lock,defer Unlock 就能简单地缩小临界区了。
HIgh CPU Usage
高CPU使用率主要可以划分为两个方面:
- Runtime High CPU USAGE
- Applys High CPU USAGE
Runtime占用CPU
调度(Scheduler)占用过多 CPU
goroutine 频繁创建与销毁会给调度造成较大的负担,调度包括两方面:任务窃取和减少阻塞。
更多的Scheduler(任务调度器)的详情请点击:GPM模型与任务调度
举个简单的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
package main
import (
"github.com/pkg/profile"
"time"
)
func main() {
defer profile.Start().Stop()
for i := 0;i<10000;i++{
go func(){
time.Sleep(time.Millisecond)
}()
}
}
查看pprof的cpu占用可以看出:
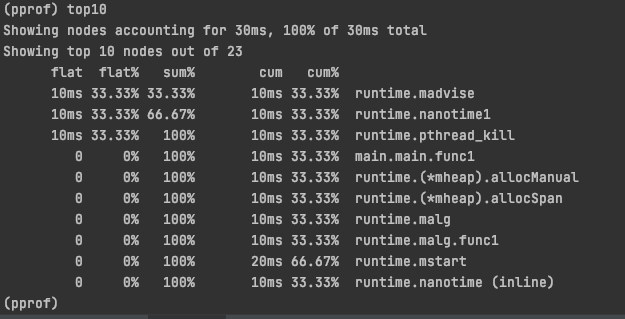
如果在 Goroutine 去执行一个 sleep 操作,导致 M 被阻塞了,Go 程序后台有一个监控线程 sysmon,它监控那些长时间运行的 G 任务然后设置可以强占的标识符,别的 Goroutine 就可以抢先进来执行,此时就需要Scheduler进行调度,把长时间的Goroutine放回去LRQ队列中等待执行。
Scheduler调度也就是我们可以看到runtime.mstart的cpu使用率是最高的。
Scheduler占用CPU优化的思路:
使用池的概念复用,有效控制占用cpu使用率
使用池的概念有效管理Goroutine,可以做Goroutine的协程池,当然也可以做任务的workPool,那么可以考虑使用开源的 workerpool 来进行改进,比较典型的 fasthttp worker pool。
gc垃圾回收占用过多 CPU

上图是一个Goroutine中使用map触发gc回收的例子
更多的gc回收的知识请看:golang-garbage-collection
GC回收占用CPU优化思路:
-
能用栈的别用堆:stack上的内存空间是Processor所拥有的mache是不用GC进行回收的空间
-
少用指针传递多用值传递:指针传递和指针对象的返回外层对象,是会发生逃逸。
更多的go逃逸分析请看:golang-escape-analysis
- 修改对象:必用对象里面引用指针,这样会使GCMark三色遍历过程花费更多资源
- 用slice去替代map:map在GC回收上要遍历buckets里面的每个bmap会让GC占用更多的CPU资源
Applys 应用占用CPU
-
比较常见的就是json转换,在序列化的过程中占用过多的CPU
解决方法:用二进制流通信例如proto
-
应用逻辑方法的CPU占用,只能用过压测还有benchmark、pprof定位优化
例如:
在使用GoMicro 1.10版本发生了一个chan没被消费导致goroutine泄露
通过压测可以看到: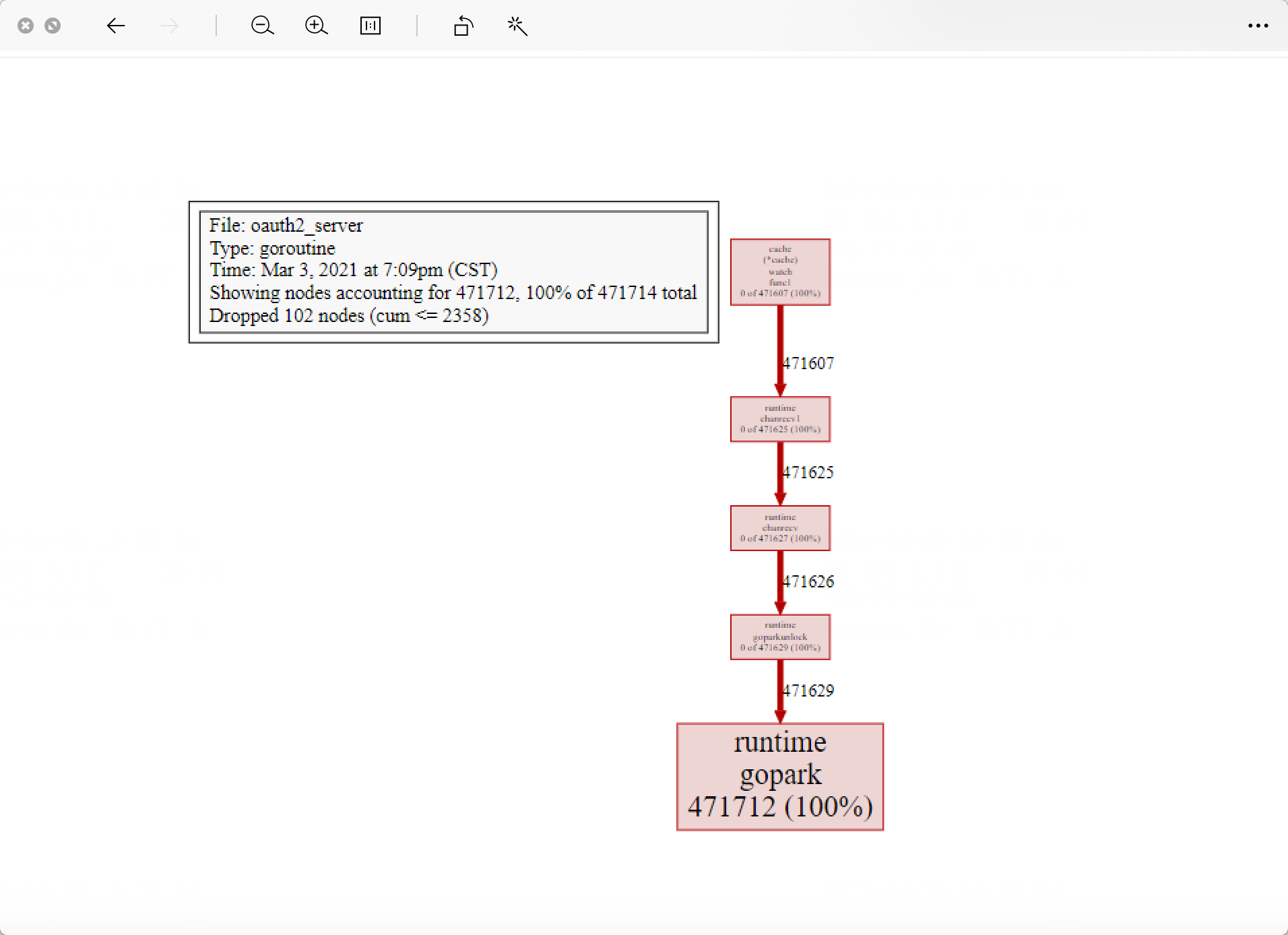
可以看到运行到runtime.gopark的goroutine数量增加了471712个
打印在运行的goroutine发现一直在增加
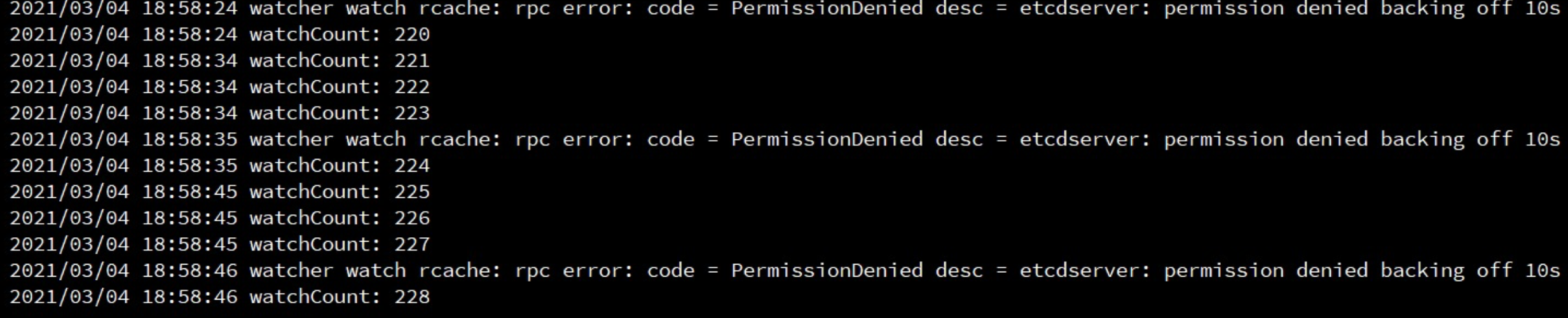
看到这个版本里面的开源库源码:
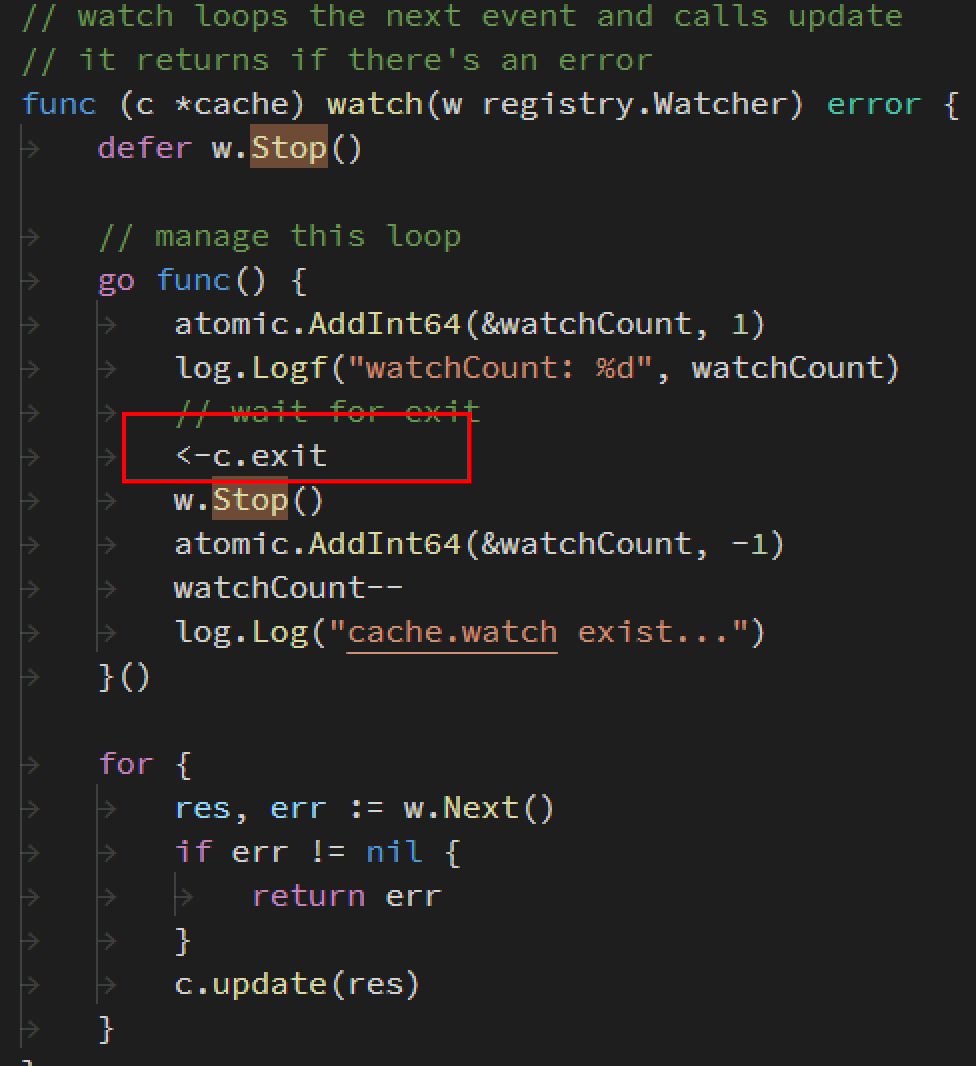
可以看到监听cache的时候Goroutine无法释放导致,goroutine泄露。
在gomicro的1.18版本修复后源码为:
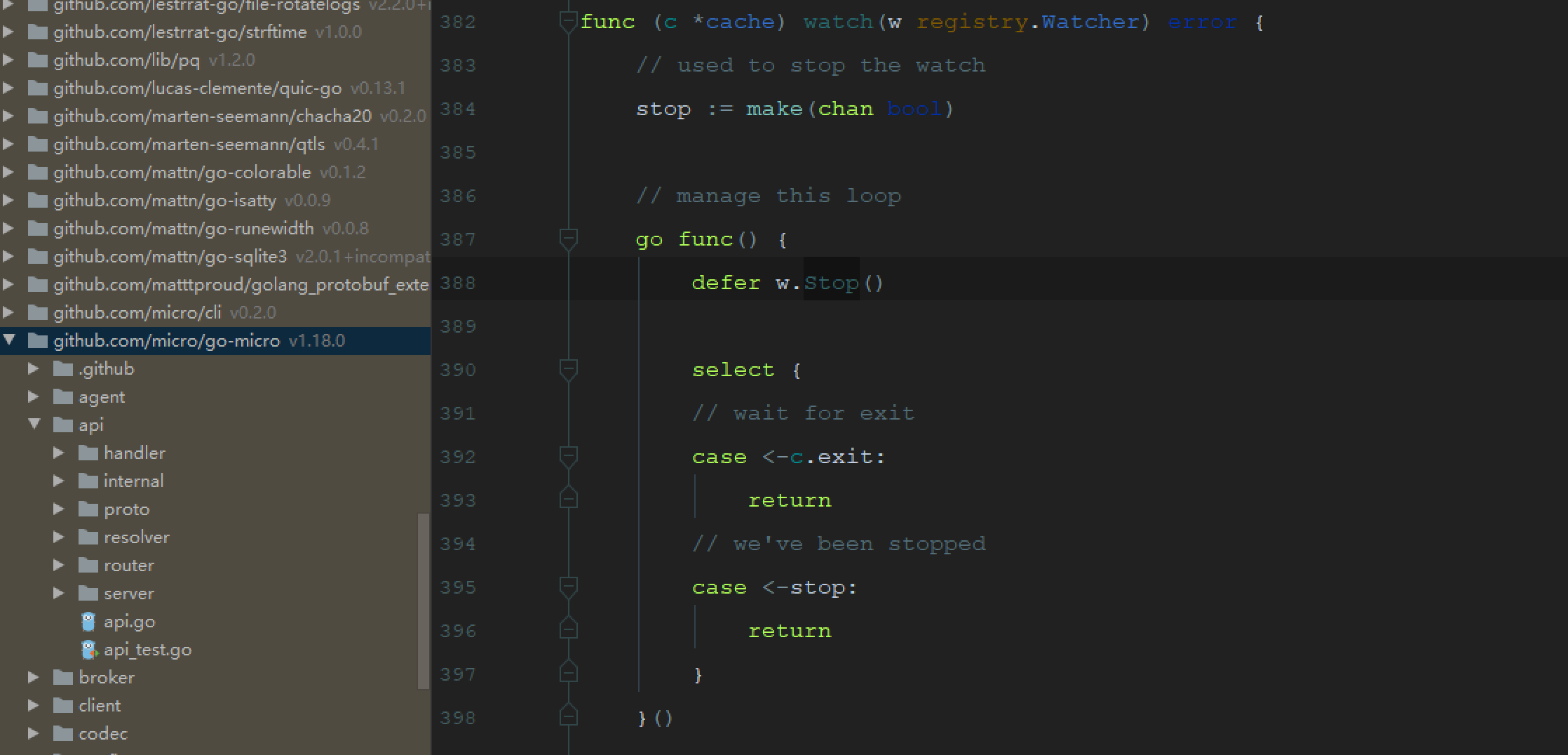
以上例子为开源库的apps-logic性能优化的参考。
High Memory usage
高内存使用率主要可以划分为两个方面:
- Heap Allocation
- Massive g Stacks
Heap Allocation 堆内存分配
当前大多数的业务后端服务是不太需要关注进程消耗的内存的。
我们经常看到做 Go 内存占用优化的是在网关(包括 mesh)、存储系统这两个场景。
例如我之前做过的:mongoServer内存优化:https://elvisng.github.io/2020/04/22/optimize-mongo-performance/
当然这个底层的就是高并发的http带来的内存损耗了。这里找到了一个Golang SDK 旧版本的bug来说明问题。
GoSDK v1.9
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
//TLS clientHandshake 证书认证的writeRecordLocked
func (c *Conn) writeRecordLocked(typ recordType, data []byte) (int, error) {
b := c.out.newBlock() =========> 重点在这里
defer c.out.freeBlock(b)
var n int
for len(data) > 0 {
...
b.data[1] = byte(vers >> 8)
b.data[2] = byte(vers) //版本
b.data[3] = byte(m >> 8) //长度
b.data[4] = byte(m)
...
copy(b.data[recordHeaderLen+explicitIVLen:], data) //拷贝数据到记录层缓存
c.out.encrypt(b, explicitIVLen)
if _, err := c.write(b.data); err != nil {
return n, err
}
n += m
data = data[m:]
}
...
}
可以看到这里是每个TLS进来都是newBlock,并且进行了数据的copy
GoSDK 1.16.2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// outBufPool pools the record-sized scratch buffers used by writeRecordLocked.
var outBufPool = sync.Pool{
New: func() interface{} {
return new([]byte)
},
}
// writeRecordLocked writes a TLS record with the given type and payload to the
// connection and updates the record layer state.
func (c *Conn) writeRecordLocked(typ recordType, data []byte) (int, error) {
outBufPtr := outBufPool.Get().(*[]byte)
outBuf := *outBufPtr
defer func() {
*outBufPtr = outBuf
outBufPool.Put(outBufPtr)
}()
var n int
for len(data) > 0 {
m := len(data)
if maxPayload := c.maxPayloadSizeForWrite(typ); m > maxPayload {
m = maxPayload
}
_, outBuf = sliceForAppend(outBuf[:0], recordHeaderLen)
outBuf[0] = byte(typ)
...
outBuf[1] = byte(vers >> 8)
outBuf[2] = byte(vers)
outBuf[3] = byte(m >> 8)
outBuf[4] = byte(m)
var err error
outBuf, err = c.out.encrypt(outBuf, data[:m], c.config.rand())
...
n += m
data = data[m:]
}
...
}
可以看到这里的版本进行了两个优化
- outBufPool是一个sync.Pool,看注释可以知道,是根据record-sized去复用buffers,复用堆上的对象
- 使用了切片去替代copy
查看1.9版本与1.16.2版本对比两者pprof相差有多大呢?
以下是以毫秒访问百度,压测30秒的数据,数据准确性有偏差,但足够看出问题了。
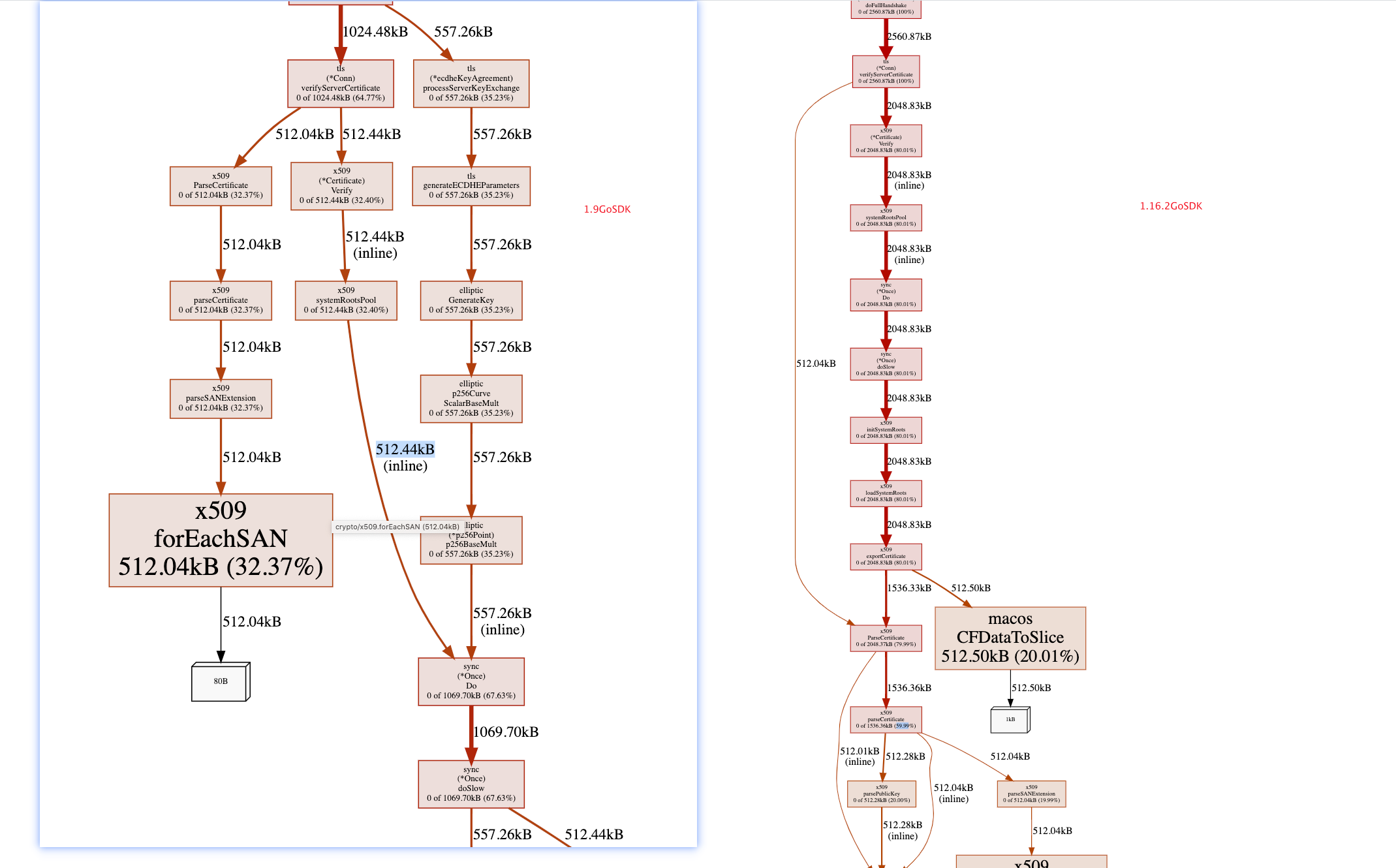
可以看出内存使用率相差接近4倍之多。
堆分配占用内存优化的思路:
减少所有内存占用:
-
goroutine 占用的栈内存
-
有效的使用slice去替代map和array
-
避免对于同级别span内存分配对象的大量读写,因为大量的同级别大小的NumSizeClasses读写,如果超过mcentral的管理的空间范围会触发mheapManager,导致堆内存分配
-
goroutineFunc内尽量不要用Sleep等操作,当goroutineSleep的时候Machine就会被阻塞,同时Sched没办法识别当前Processor所挂载的
mcache是否能回收释放,为gc添压力的同时如果队列LRQ队列过长,mcentral中的span会进一步消耗导致堆内存进行无效分配。
-
-
read buffer 和 write buffer 占用的内存
- 合理应用sync.Pool,如上面的GoSDK例子
Massive g Stacks 大量的Goroutine的栈内存
我们被教导goroutine的不像thread, 它是很便宜的,可以在服务器上启动成千上万的goroutine。但是对于一百万的连接,这种goroutine-per-connection的模式就至少要启动一百万个goroutine,这对资源的消耗也是极大的。
goroutine锁使用的最小的buffer栈大小是2KB,一百万个也就几G的空间出去了。
goroutine-per-connection模式(一协程一连接):
其实netPoller的实现也是epoll
Massive g Stacks优化思路:
goroutine-per-connection 方式不能说是Golang的设计缺陷,其实本意是将Go 语言将该“复杂性”隐藏在 Runtime 中:Go 开发者无需关注 socket 是否是 non-block 的,也无需亲自注册文件描述符的回调,只需在每个连接对应的 Goroutine 中以“block I/O”的方式对待 socket 处理即可。但是大量的 Goroutine 也会带来额外的问题,比如栈内存增加和调度器负担加重。
那么,其实优化思路也就随之而来了,用epoll方式去外部实现代替,自己来管理网络读写。
其实就是建立起一个Goroutine来管理网络事件进行读写, gorouting监听数据到来的事件,每次只最多读取100个事件。
详细实现过程可以看大佬的文章:百万 Go TCP 连接的思考: epoll方式减少资源占用:https://colobu.com/2019/02/23/1m-go-tcp-connection/
smallnest的文章写得很好,这里就不再赘述了。
文章的局限性
本文中都基本是常见的性能问题,可以通过压测和数据去分析的,但实际生产中有OOM这种无法通过性能分析去优化的
也有更多的是应用代码层的东西是要通过case by case去分析的,所以还是多动手去试试吧~
思其意不思其辞,哪怕一模一样的东西,自己动手比看的都深刻。