Linux存储基础知识
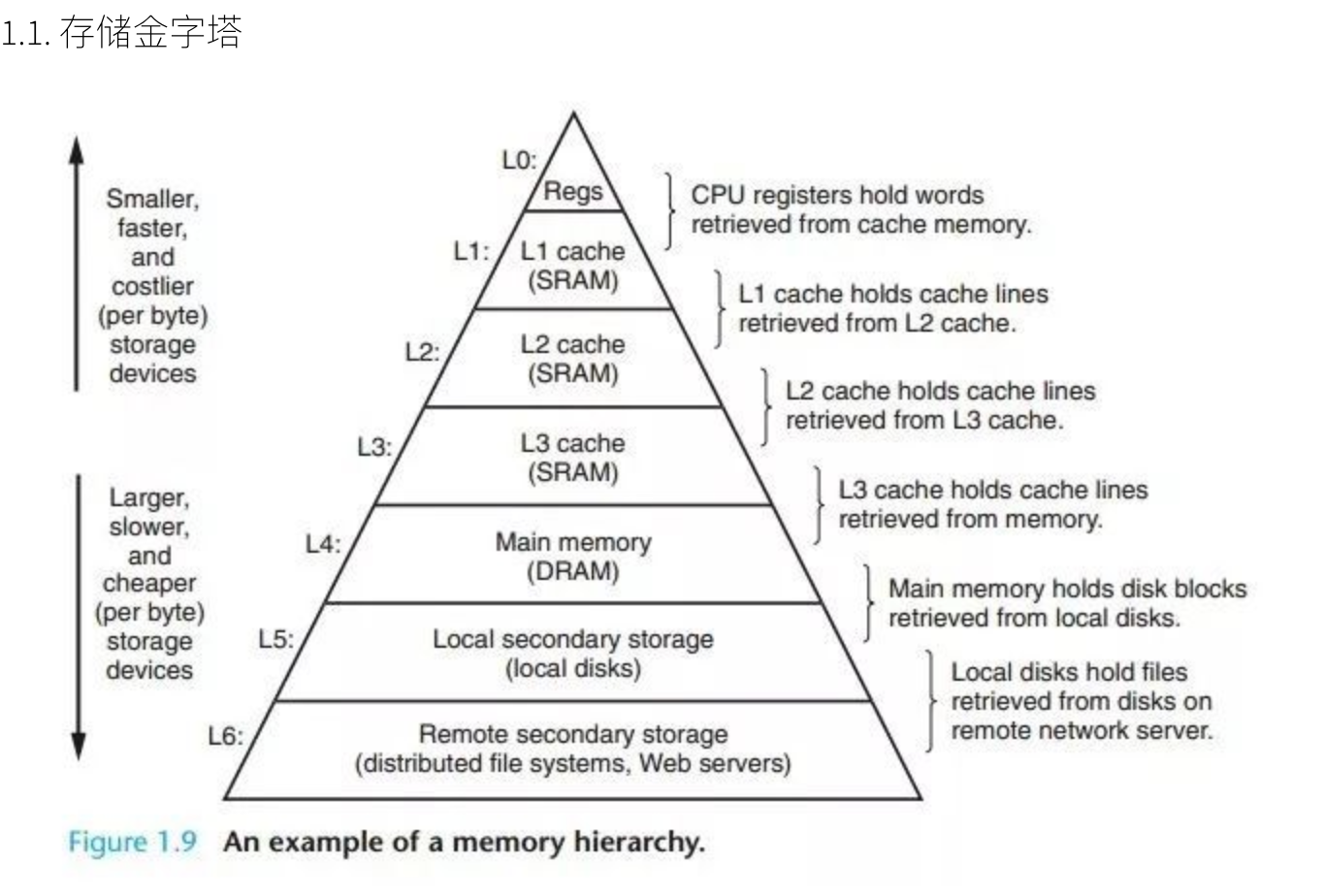
-
CPU寄存器
- L1(CPU-Cache)
- L2(CPU-Cache)
-
L3(CPU-Cache)
-
物理内存
- 硬盘等辅助存储设备
- 鼠标等外接设备
虚拟内存
虚拟内存是对于进程来说的,屏蔽了底层的RAM和硬盘,提供了进程的运转的可靠保证。我们来看一下虚拟内存的分层设计。

上图展示了某进程访问数据,当RAM-Cache没有命中的时候,访问虚拟内存获取数据的过程。在访问内存,实际访问的是虚拟内存,虚拟内存通过page查看,当前要访问的虚拟内存地址,是否已经加载到了物理内存。如果已经在物理内存,则取物理内存数据,如果没有对应的物理内存,则从磁盘加载数据到物理内存,并把物理内存地址和虚拟内存地址更新到page。
为什么要有虚拟内存?
可以思考一下,如果进程如果直接对于物理内存访问,当多进程同时访问一个物理内存空间的时候会产生的并发问题。虚拟内存的引入使得各个进程都拥有各自的虚拟内存空间,内存的并发访问问题的粒度从多进程级别,可以降低到多线程级别。
栈和堆
从虚拟内存部分可以知道,虚拟内存的存在已经将并发降低到线程级别,那么我们是怎么去处理多线程的内存的控制的呢,请看堆和栈。
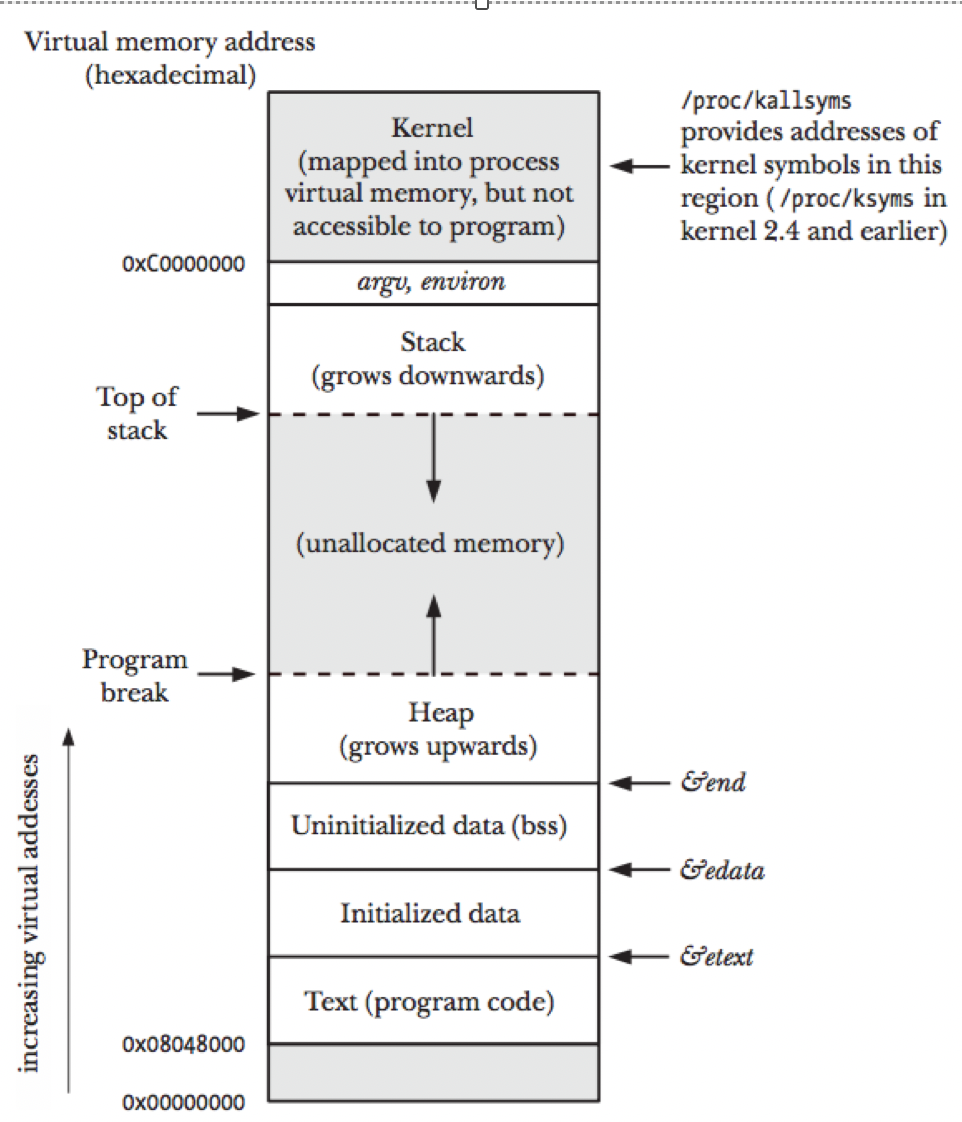
栈和堆只是虚拟内存上2块不同功能的内存区域:
- 栈在高地址,从高地址向低地址增长
- 堆在低地址,从低地址向高地址增长
栈和堆相比有这么几个好处:
- 栈的内存管理简单,分配比堆上快。
- 栈的内存不需要回收,而堆需要进行回收,无论是主动free,还是被动的垃圾回收,这都需要花费额外的CPU。
- 栈上的内存有更好的局部性,堆上内存访问就不那么友好了,CPU访问的2块数据可能在不同的页上,CPU访问数据的时间可能就上去了
堆内存
从上面的知识可以知道,当我们说内存管理的时候,主要是指堆内存的管理,因为栈的内存管理不需要开发者去操心的,那么系统是怎么对于堆内存管理的呢
请看下图:
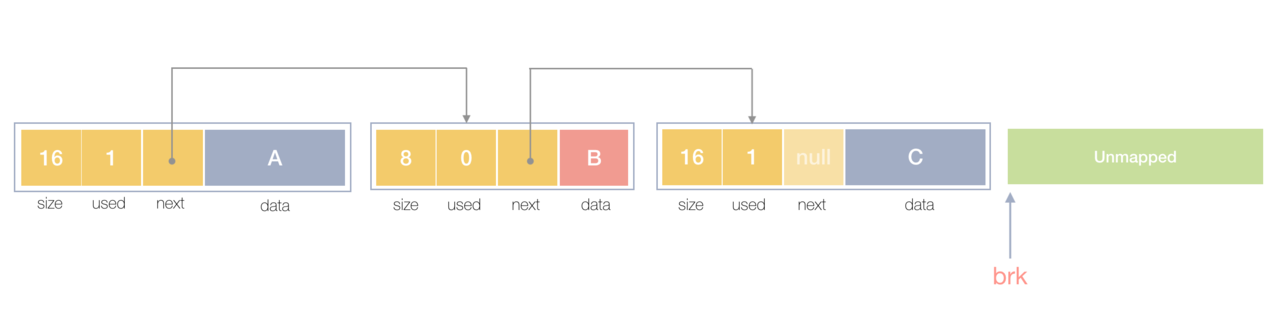
堆内存的实质就是一个个内存块用链表相连;每个内存块的基本信息,比如大小(size)、是否使用中(used)和下一个内存块的地址(next),内存块实际数据存储在data中。
堆内存释放
那么什么是内存的释放呢,实质是把使用的内存块从链表中取出来,然后标记为未使用,当分配内存块的时候,可以从未使用内存块中优先查找大小相近的内存块,如果找不到,再从未分配的内存中分配内存。
伴随着不断的申请释放,会出现越来越多不合适的内存碎片,也就伴随着申请一块合适的内存大小的遍历成本增大,从而降低内存的使用效率,linux对于这个问题解决办法是将2个连续未使用的内存空间合并。
但我们都知道这种简单的线性合并对于遍历的效率提升并不高,从而慢慢的就出现了很多内存管理库。
比如glibc的ptmalloc,FreeBSD的jemalloc,Google的tcmalloc等等,为何会出现这么多的内存管理库?本质都是在多线程编程下,追求更高内存管理效率:更快的分配是主要目的。
想了解更多的内存管理,可以阅读这篇文章Writing a Memory Allocator
TCMalloc
TCMalloc是Thread Cache Malloc的简称,是Go内存管理的起源,Go的内存管理是借鉴了TCMalloc。
我们前面提到引入虚拟内存后,让内存的并发访问问题的粒度从多进程级别,降低到多线程级别。然而同一进程下的所有线程共享相同的内存空间,它们申请内存时需要加锁,如果不加锁就存在同一块内存被2个线程同时访问的问题。
TCMalloc是怎么处理这个问题的呢?
为每一个线程预分配一块缓存空间,线程申请小内存的时候,可以直接从缓存分配。
* 在线程获取内存的时候直接从各自对应的缓存空间获取,访问的是不同的地址空间,从而无需加锁,把内存并发访问的粒度进一步降低。
* 这样分配的好处还能减少系统调用,线程都是在用户态执行的,缩短了内存总体的分配和释放时间。
基本原理
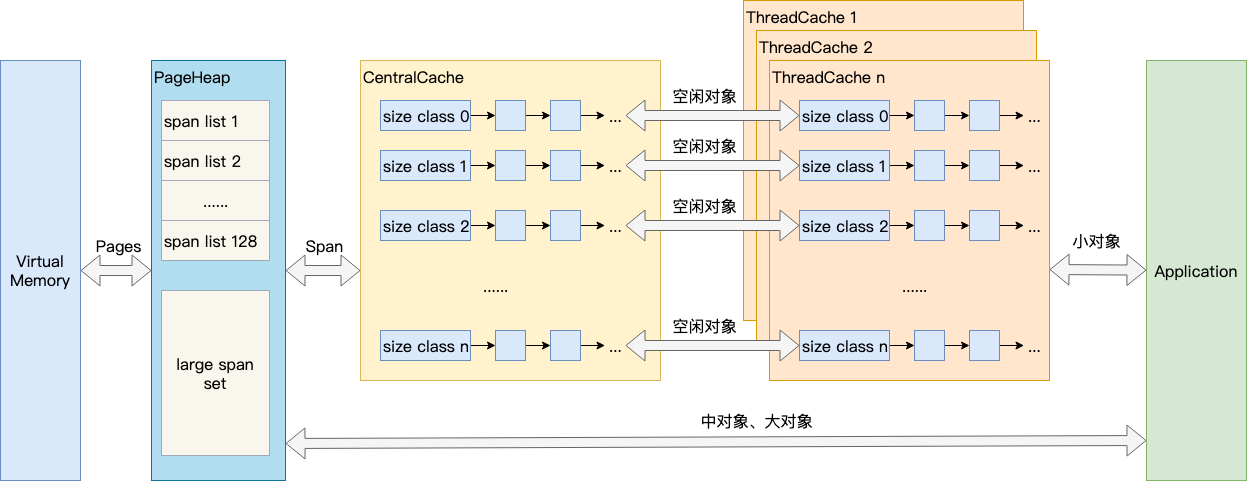
结合上图,介绍TCMalloc的几个重要概念:
- Page
操作系统对内存管理以页为单位,TCMalloc也是这样,只不过TCMalloc里的Page大小与操作系统里的大小并不一定相等。
- Span
一组连续的Page被称为Span,Span是TCMalloc中内存管理的基本单位。
- ThreadCache
ThreadCache是每个线程各自的Cache,一个Cache包含多个空闲内存块链表,每个链表连接的都是内存块,同一个链表上内存块的大小是相同的,也可以说按内存块大小,给内存块分了个类,这样可以根据申请的内存大小,快速从合适的链表选择空闲内存块。由于每个线程有自己的ThreadCache,所以ThreadCache访问是无锁的。
- CentralCache
CentralCache是所有线程共享的缓存,也是保存的空闲内存块链表,链表的数量与ThreadCache中链表数量一一对应,当ThreadCache的内存块不足时,可以从CentralCache获取内存块;当ThreadCache内存块过多时,可以放回CentralCache。由于CentralCache是线程共享的,所以它的访问是要加锁的。
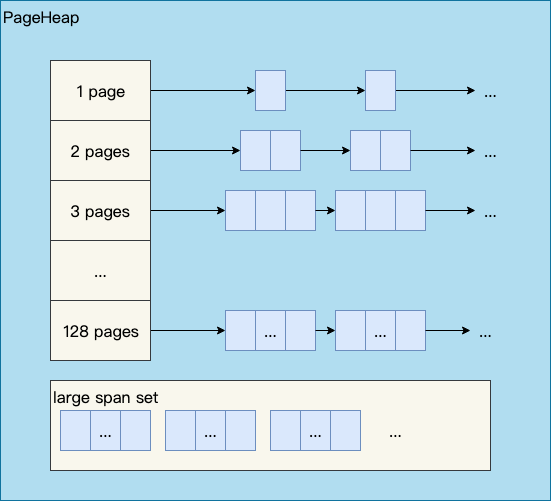
- PageHeap
PageHeap是对堆内存的抽象,当CentralCache的内存不足时,会从PageHeap获取空闲的内存Span,然后把1个Span拆成若干内存块,添加到对应大小的链表中并分配内存;当CentralCache的内存过多时,会把空闲的内存块放回PageHeap中。
其次中、大对象的内存直接由PageHeap来分配。
上面提到了小、中、大对象,Go内存管理中也有类似的概念,我们看一眼TCMalloc的定义:
- 小对象大小:0~256KB
- 中对象大小:257~1MB
- 大对象大小:>1MB
小对象的分配流程:ThreadCache -> CentralCache -> HeapPage,大部分时候,ThreadCache缓存都是足够的,不需要去访问CentralCache和HeapPage,无系统调用配合无锁分配,分配效率是非常高的。
中对象分配流程:直接在PageHeap中选择适当的大小即可,128 Page的Span所保存的最大内存就是1MB。
大对象分配流程:从large span set选择合适数量的页面组成span,用来存储数据。
如果我们掌握了上面的TCMalloc的内存分配思想,下面的Go内存分配就很简单了~
Go内存管理
前文提到Go内存管理源自TCMalloc,但它比TCMalloc还多了2件东西:逃逸分析和垃圾回收。
这两块我都分开了一篇文章介绍,请看:
Go垃圾回收:golang-garbage-collection
Go逃逸分析:golang-escape-analysis
基本原理
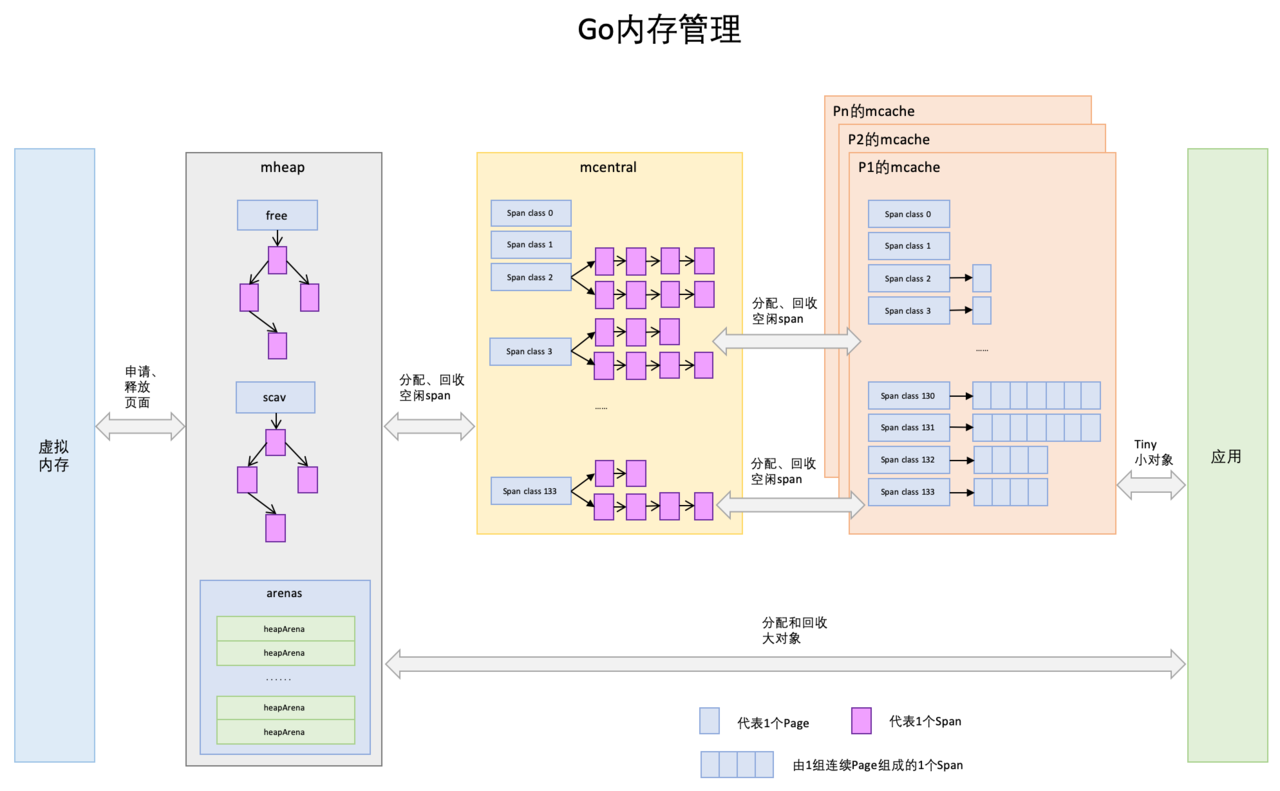
- Page
与TCMalloc中的Page相同,是Go对于堆内存的抽象的基本单位,1个浅蓝色的长方形代表1个Page。
- Span
Span与TCMalloc中的Span相同,Span是内存管理的基本单位,代码中为mspan,一组连续的Page组成1个Span,所以上图一组连续的浅蓝色长方形代表的是一组Page组成的1个Span,另外,1个淡紫色长方形为1个Span。
- mcache
mcache与TCMalloc中的ThreadCache类似,但我们知道Go中并不用Thread,所以对应的就是Goroutine,TCMalloc中是每个线程1个ThreadCache,Go中是每个P拥有1个mcache。
mcache保存的是各种大小的Span,并按Span class分类,小对象直接从mcache分配内存,它起到了缓存的作用,并且可以无锁访问。为go的并发处理的快速提供了可靠的保证。
- mcentral
mcentral与TCMalloc中的CentralCache类似,是所有线程共享的缓存,需要加锁访问。它按Span级别对Span分类,然后串联成链表,当mcache的某个级别Span的内存被分配光时,它会向mcentral申请1个当前级别的Span。
但是mcentral与CentralCache也有不同点,CentralCache是每个级别的Span有1个链表,mcache是每个级别的Span有2个链表,这和mcache申请内存有关,Go中对于指针对象的分配和非指针对象的分配是指向不同的空间的。
- mheap
mheap把从OS申请出的内存页组织成Span,并保存起来。并且把span组成了两颗结构树:free、scav,把Span分配到heapArena进行管理,它包含地址映射和span是否包含指针等位图,这样做的主要原因是为了更高效的利用内存:分配、回收和再利用。
mheap本身是一个全局变量,当mheap的Span不够用时会向OS申请内存并形成span,mcentral的Span不够用时会向mheap申请,所以会有并发问题,同样也是需要加锁访问的。
那么Goroutine管理的mcache跟object是怎么对应的呢?
这里面有几个概念:
- object size:代码里简称size,指object申请内存的对象大小。
- size class:代码里简称class,它是size的级别,相当于把size归类到一定大小的区间段,比如size[1,8]属于size class 1,size(8,16]属于size class 2。
- span class:mcache对应的存储单位。span class主要用来和size class做对应,这里知识说的对应,不代表size class 1 对应 span class 1。 1个size class对应2个span class,2个span class的span大小相同,只是功能不同,1个用来存放包含指针的对象,一个用来存放不包含指针的对象,不包含指针对象的Span就无需GC扫描了。这样就降低了GC&CPU的负担。
- num of page:代码里简称npage,代表Page的数量,就是Span包含的页数,一组连续的Page组成1个Span。
Go内存分配
先来清楚对象大小的分类才知道分配的是什么
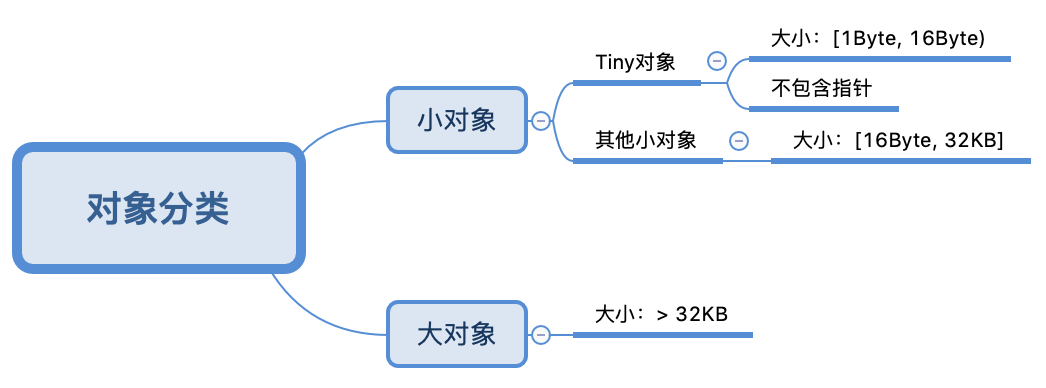
当明白了上面的知识,我们举一个不包含指针的,大小为24Byte的对象为例子来简单说说Go内存的分配。
例子
一个大小为24byte的对象对应的size class为3,它的对象大小范围是(16,32]Byte,24Byte刚好在此区间,所以此对象的size class为3。
Size class到span class的计算如下:
1
2
3
4
5
6
// noscan为true代表对象不包含指针
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}
// 结果
span class = 3 << 1 | 1 = 7
所以对应的span class 7
- 从span分配对象空间
传入的sizeclass为uint8,所以对应的span大小为8kb,每个实际对象所占大小为32 byte,计算可得出,span被拆分为256块,根据起始地址可以知道每个对象块的地址。

随着内存的分配,span中的对象内存块,有些被占用,有些未被占用,比如上图,整体代表1个span,蓝色块代表已被占用内存,绿色块代表未被占用内存。当分配内存时,只要快速找到第一个可用的绿色块,并计算出内存地址即可,如果需要还可以对内存块数据清零。
当span内的所有内存块都被占用时,没有剩余空间继续分配对象,mcache会向mcentral申请1个span,mcache拿到span后继续分配对象。
- mcache向mcentral申请span
mcentral和mcache一样,都是0~133这134个span class级别,但每个级别都保存了2个span list,即2个span链表:
-
nonempty:这个链表里的span,所有span都至少有1个空闲的对象空间。这些span是mcache释放span时加入到该链表的。
-
empty:这个链表里的span,所有的span都不确定里面是否有空闲的对象空间。当一个span交给mcache的时候,就会加入到empty链表。
分配逻辑是这样的:
mcache向mcentral申请span时,mcentral会先从nonempty搜索满足条件的span,如果没有找到再从emtpy搜索满足条件的span(满足条件的span即已标记为垃圾的span,这样清理后即可提供mache使用),然后把找到的span交给mcache。
- mheap的span管理
mheap里保存了两棵二叉排序树,按span的page数量进行排序:
- free:free中保存的span是空闲并且非垃圾回收的span。
- scav:scav中保存的是空闲并且已经垃圾回收的span。
如果是垃圾回收导致的span释放,span会被加入到scav,否则加入到free,比如刚从OS申请的的内存也组成的Span。

mheap中还有arenas,由一组heapArena组成,Go就用全局的mheap来管理堆内存的分配和GC的回收
- mcentral向mheap申请span
当mcentral向mcache提供span时,如果empty里也没有符合条件的span,mcentral会向mheap申请span。
此时,mcentral需要向mheap提供需要的内存页数和span class级别,然后它优先从free中搜索可用的span。如果没有找到,会从scav中搜索可用的span。如果还没有找到,它会向OS申请内存,再重新搜索2棵树,必然能找到span。如果找到的span比需要的span大,则把span进行分割成2个span,其中1个刚好是需求大小,把剩下的span再加入到free中去,然后设置需要的span的基本信息,然后交给mcentral。此时的操作是要加锁的。
- mheap向OS申请内存
当mheap没有足够的内存时,mheap会向OS申请内存,把申请的内存页保存为span,然后把span插入到free树。在32位系统中,mheap还会预留一部分空间,当mheap没有空间时,先从预留空间申请,如果预留空间内存也没有了,才向OS申请。
文章总结
总体的Go内存分配原理就是以上,它主要强调两个重要的思想:
- 使用缓存提高效率。Go内存分配和管理也使用了缓存,利用缓存一是减少了系统调用的次数,二是降低了锁的粒度、减少加锁的次数,从这2点提高了内存管理效率。
- 以空间换时间,提高内存管理效率。牺牲掉提前分配好的小内存空间,换成快速的访问时间。空间换时间是一种常用的性能优化思想,数据库中也很常见,比如数据库索引、索引视图和数据缓存等,再如Redis等缓存数据库也是空间换时间的思想。