现状:
背景:
从离职旧同事手上接过来一个活,线上旧应用数飞速猛涨,应用的复工复学的带来某时段的刚需用户登录数几何级上升。
应用现状:
- 前置GATE横向扩容导致刚需流量直接灌入后端登录应用
- 采用了Mongo数据库并不是缓存数据库,数据存储时采用内存到文件映射导致内存飙高
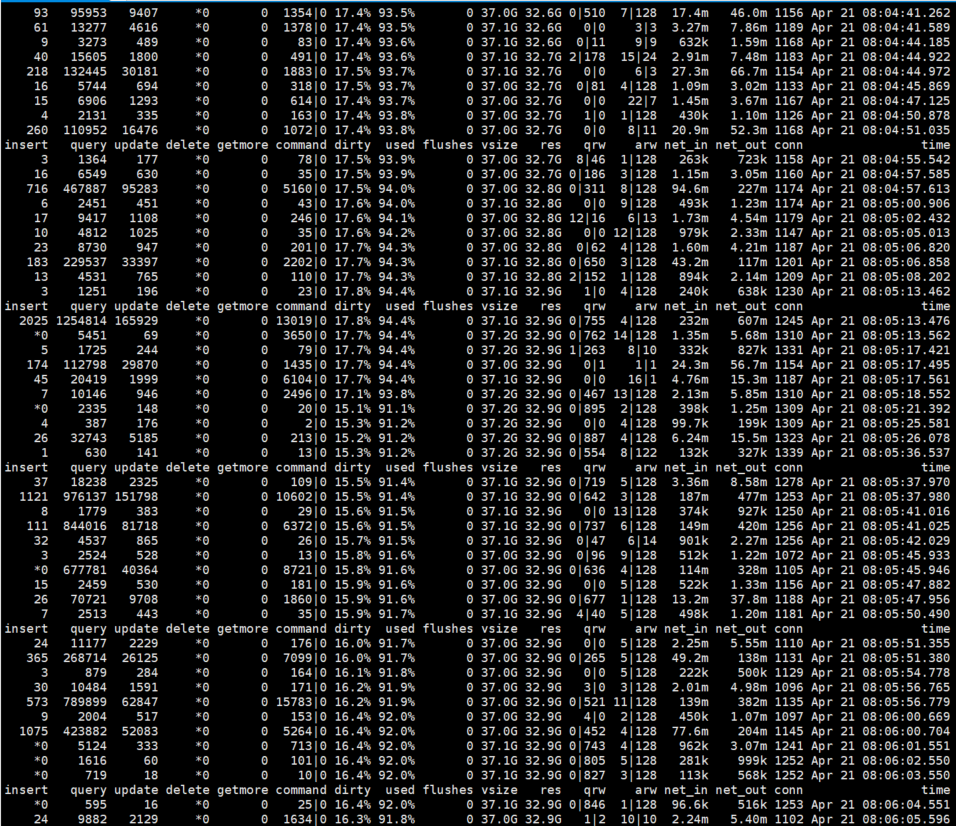
- Mongo过旧采用单节点状态, 峰值tps几乎已经到达节点上限,同時平均服务器IO已到达100%,随着读写流量的进一步增加,时延抖动严重影响应用的可用性
- 应用链接采用的是简单的数据库链接模式,随着流量执行数据量超过150万/秒,MongoServer内部的阻塞队列和Dirty率飙高超过20%,内存使用率也超90%,wiredtiger存儲引擎明显跟不上语句执行速度。
高峰时的Mongo服务器IO:

高峰时的MongoStat:
优化方案:
在几日内无法增加服務器资源的情況下,首先做了如下层面的优化,并取得了理想的数倍性能提升:
-
业务层面优化
-
Mongodb配置优化
-
Mongodb存儲引擎WiredTiger優化
后期长期优化方案
-
低等级横向扩容,增加内存,增加SSD,增加读写速率,使得数据有足够的空间映射到内存中提高数据的读写速率,降低服务器的IO
-
横向扩容,双主方案,hash流量降低40%的流量与读写。
-
横向扩容,加机器,做副本集,读写分离。(需解决多条件查询的数据融合问题)
因为机器和数据融合查询问题,最后选择2的方案优化,采用mongoshake和mongo原生互为主从方案 详情
业务层面优化
-
缓存数据,减少数据读Mongo。由于监控到数据库的大量读的操作,故优化代码保留数据对象在缓存多次使用,优化业务流程只要数据还在有效期内减少写操作。
-
因应用老旧,使用的还是mongo-go-driver v0.0.3,不支持多语句执行提交,故升级版本mongo-go-driver v1.3.2,批量执行写入和更新,减少数据库请求次数,降低mongo Db网络IO。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
func DemoMongo() { // insert many users NewUsers := make([]User, 1) NewUsers = append(NewUsers, User{ Username: "userB", Psw: "123", }, User{ Username: "userC", Psw: "123", }) if res, err := InsertManyUsers(NewUsers); err != nil { return } else { fmt.Printf("inserted ids: %v\n", res.InsertedIDs) } }
-
Mongodb客户端连接优化(采用mongo连接池优化,减少交互与网络IO,增加Socket网络超时优化程序)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
func initMongo() (err error) { log.Printf("initMongo:%#v\n", Conf.DB) hosts := Conf.DB.Mongo dbUser := Conf.DB.DbUser dbPwd := Conf.DB.DbPwd uri := fmt.Sprintf("mongodb://%s", hosts) if dbUser != "" { uri = fmt.Sprintf("mongodb://%s:%s@%s/%s", dbUser, dbPwd, hosts, "admin") } mongoMaxConnsPerHost := 200 mongoMaxIdleConnsPerHost := 200 mongoMaxConnIdleTime := 60 * time.Second socketTimeout := 10 * time.Second if Conf.DB.MongoMaxConnsPerHost > 0 { mongoMaxConnsPerHost = Conf.DB.MongoMaxConnsPerHost } if Conf.DB.MongoMaxIdleConnsPerHost > 0 { mongoMaxIdleConnsPerHost = Conf.DB.MongoMaxIdleConnsPerHost } if Conf.DB.MongoMaxConnIdleTime > 0 { mongoMaxConnIdleTime = Conf.DB.MongoMaxConnIdleTime * time.Second } if Conf.DB.MongoSocketTimeout > 0 { socketTimeout = Conf.DB.MongoSocketTimeout * time.Second } mgoopt := mongo.ClientOpt.MaxConnsPerHost(uint16(mongoMaxConnsPerHost)). MaxIdleConnsPerHost(uint16(mongoMaxIdleConnsPerHost)).MaxConnIdleTime(mongoMaxConnIdleTime).SocketTimeout(socketTimeout) var client *mongo.Client if Conf.DB.MongoUseDefaultConf { client, err = mongo.NewClient(uri) if err != nil { fmt.Printf("mongo new client failed: %s", err.Error()) return } } else { client, err = mongo.NewClientWithOptions( uri, mgoopt, ) if err != nil { fmt.Printf("mongo new client failed: %s", err.Error()) return } } mgo = client.Database("dbname") return nil }
Mongodb配置优化 (网络IO复用,网络IO和磁盘IO做分离)
为什么要做网络IO复用分离
-
Mongo在高并发的情况下,q瞬间就会创建大量的线程,例如线上的这个单机,连接数会瞬间增加到上千个,也就是操作系统需要瞬间创建上千个线程,这样系统load负载就会很高。
-
此外,当链接请求处理完,进入流量低峰期的时候,客户端连接池回收链接,这时候mongodb服务端就需要销毁线程,这样进一步加剧了系统负载,同时进一步增加了数据库的抖动,特别是在PHP这种短链接业务中更加明显,频繁的创建线程销毁线程造成系统高负债。
-
一个链接一个线程,该线程除了负责网络收发外,还负责写数据到存储引擎,整个网络 I/O 处理和磁盘 I/O 处理都由同一个线程负责,本身架构设计就是一个缺陷。
Mongodb配置优化方法
-
引入serviceExecutor: adaptive配置
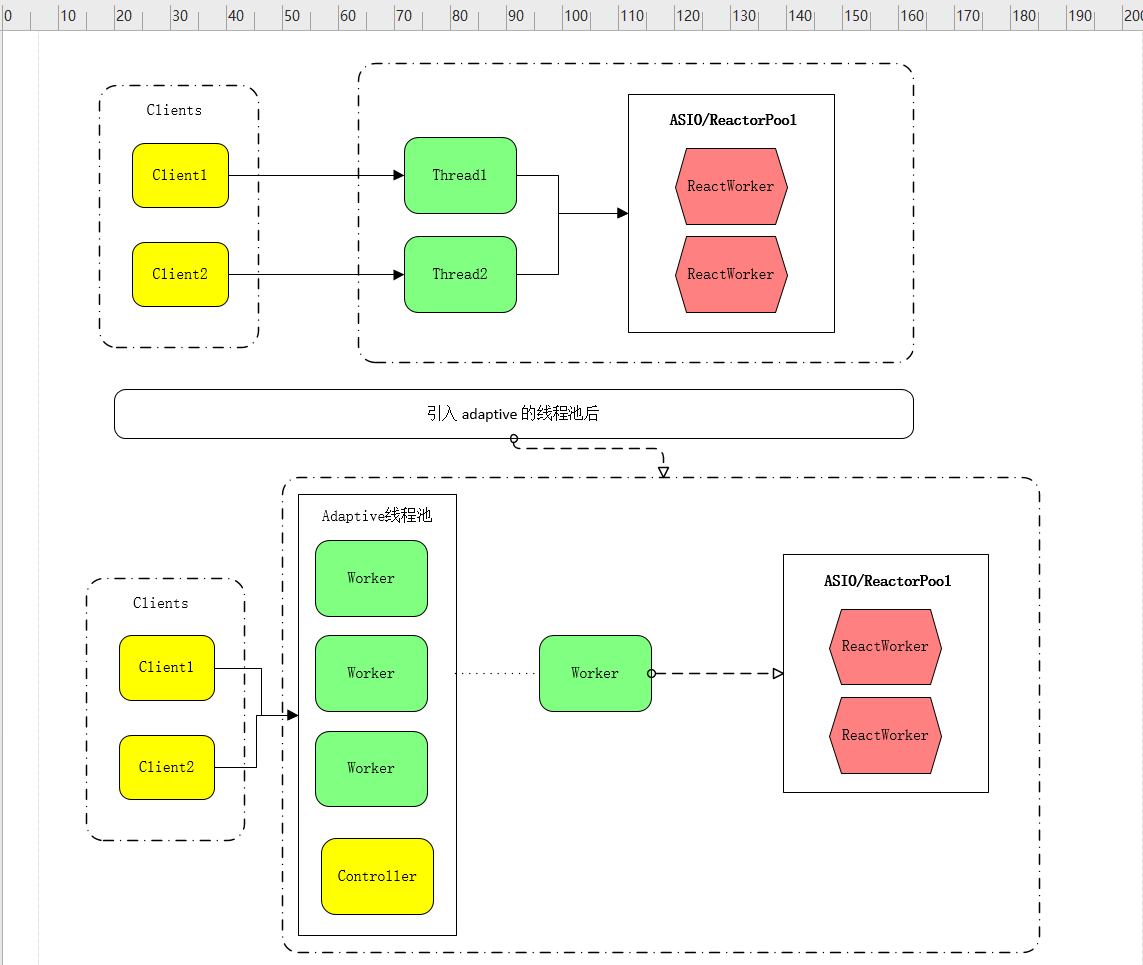
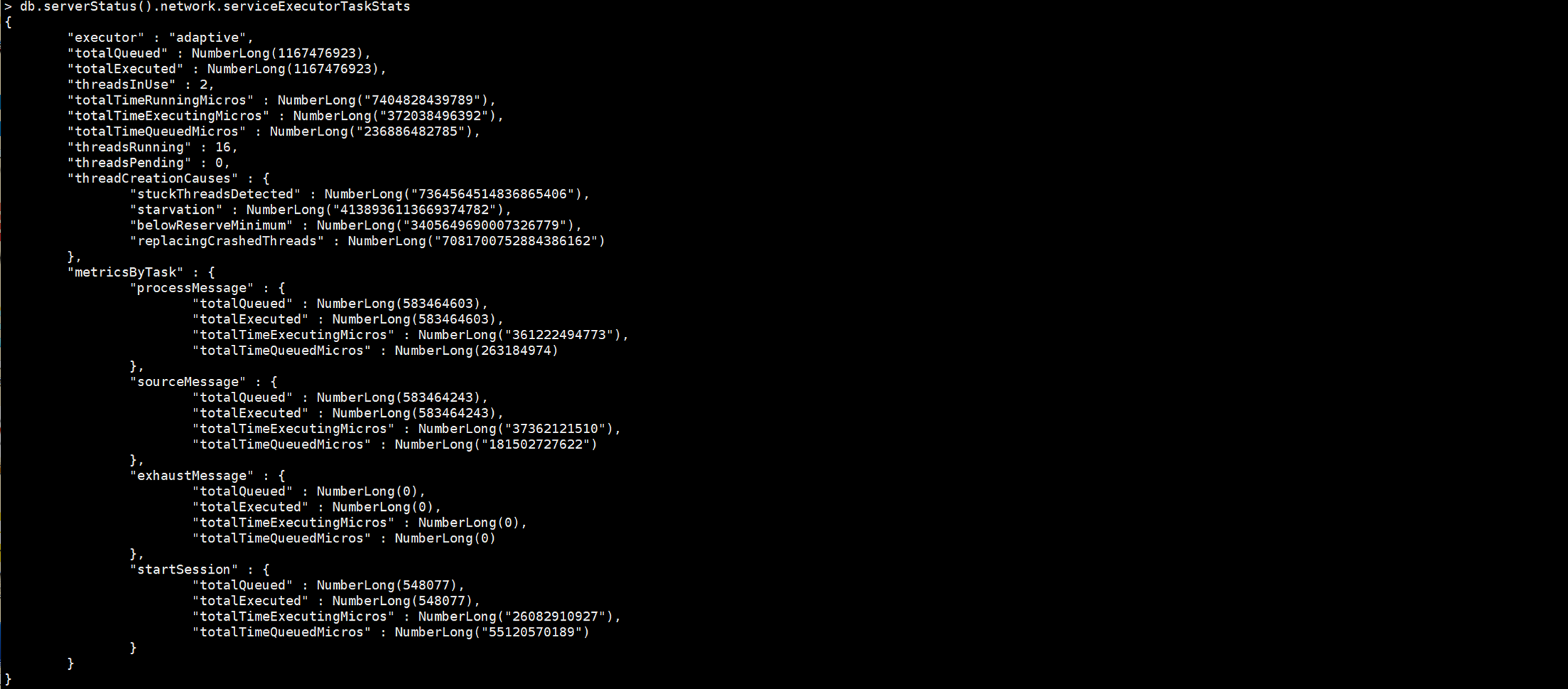
该配置根据请求数动态调整网络线程数,并尽量做到网络IO复用来降低线程创建消耗引起的系统高负载问题。加上 serviceExecutor: adaptive配置后,借助boost:asio网络模块实现网络IO复用,同时实现网络IO和磁盘IO分离。这样高并发情况下,Mongo通过自身创建的Worker调用网络链接IO复用和mongodb的锁操作来控制磁盘IO访问线程数,最终降低了大量线程创建和消耗带来的高系统负载,最终通过该方式提升高并发读写性能。
优化方案结构如下图:
adaptive打开后NetWorker处理的线程效率:
-
增加热数据缓存,减少重复IO。
根据数据存量计算出日活数据大概在1500万左右,Mongo数据的压缩比大概到40%-50%,就算出热数据大概在30G,加上18G索引数据,总缓存大概占用78G,32G缓存调整到96G,热数据缓存减少重复的磁盘IO
以上两点CS端模型优化前后MongoIO对比:
CS端模型优化是直接从调用层面降低调用与连接数,进而数据库与服务器的压力,使得服务器IO与数据库链接降低数倍。
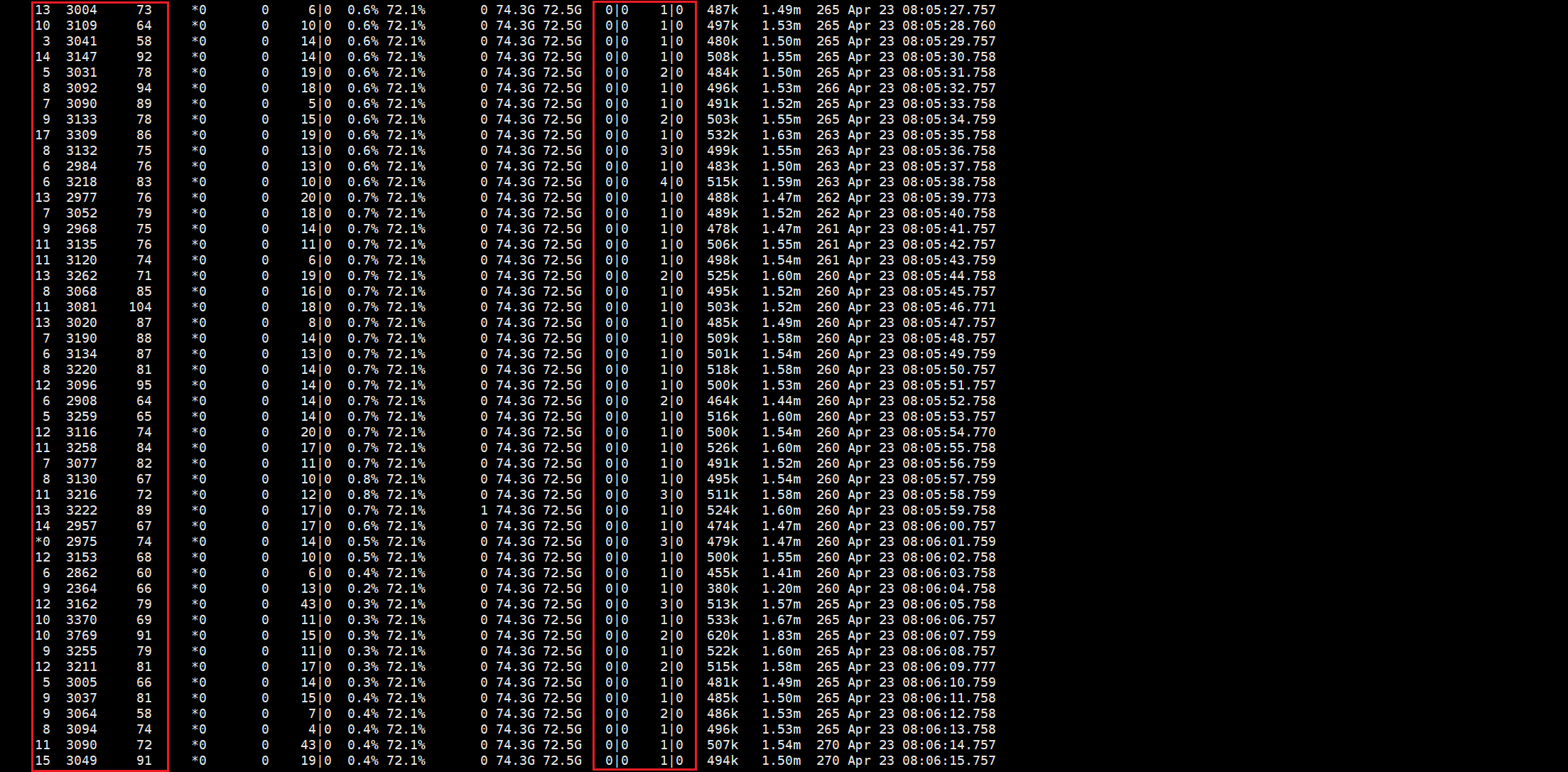
Mongo连接数降低4倍,MongoClient的连接池与MongoServer的Worker管理,sql执行量明显地降低,读写阻塞从数千降低接近与零。具体数据如下图:
优化前-MongoStat:
优化后的MongoStat:
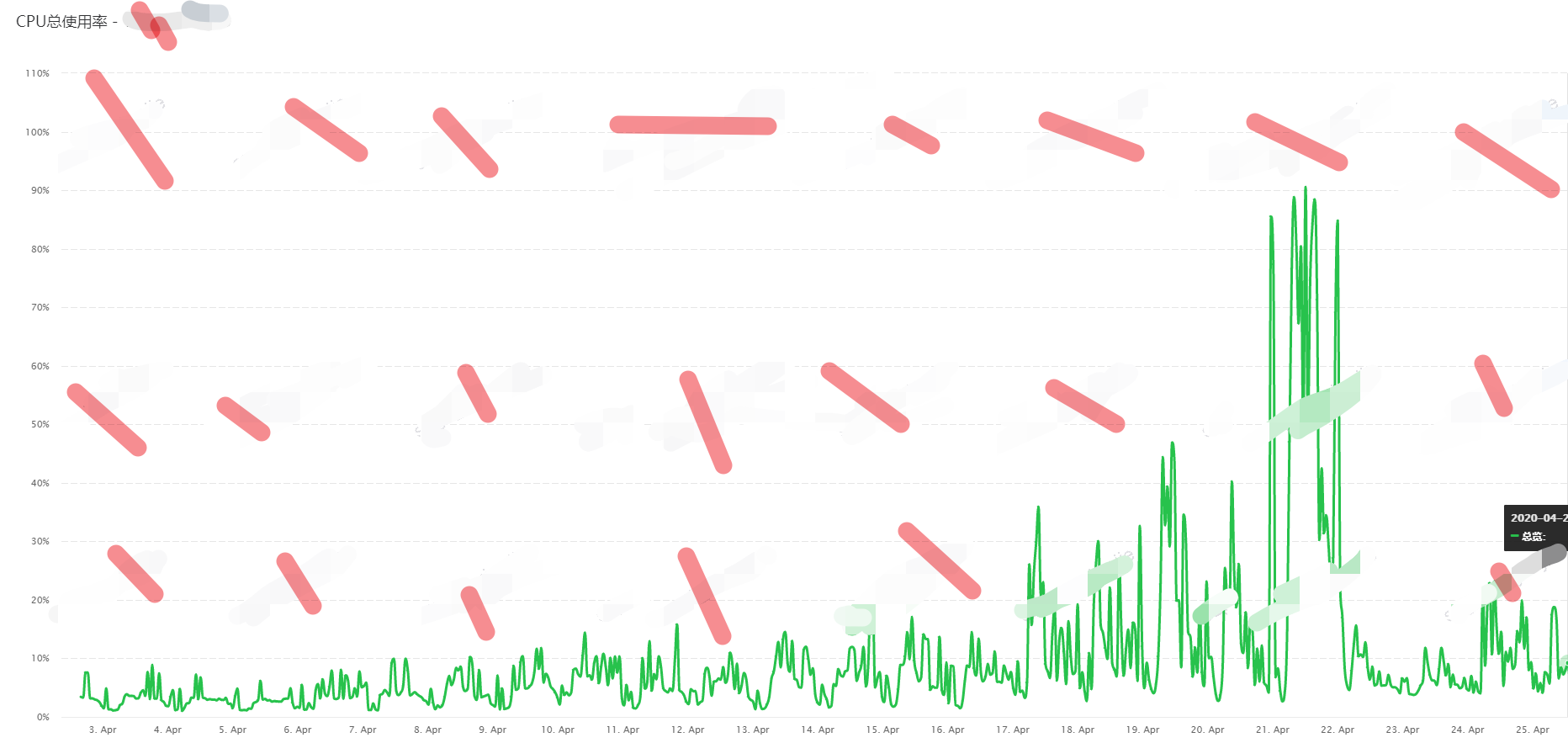
数据库服务器优化前后服务器性能对比:
优化后的服务器磁盘IO得到了大幅度的降低,从满载的超100%到优化后的低于50%,CPU也得到了释放,从迫近100%降低到20%左右的稳定。具体数据如下图:
服务器磁盘IO对比图:

服务器CPU对比图:
以上为CS端优化情况,下面是底层存储引擎的优化。
Mongodb存儲引擎WiredTiger優化
谈到存储引擎优化,我们先来了解一下Mongo的读写流程,如下图:
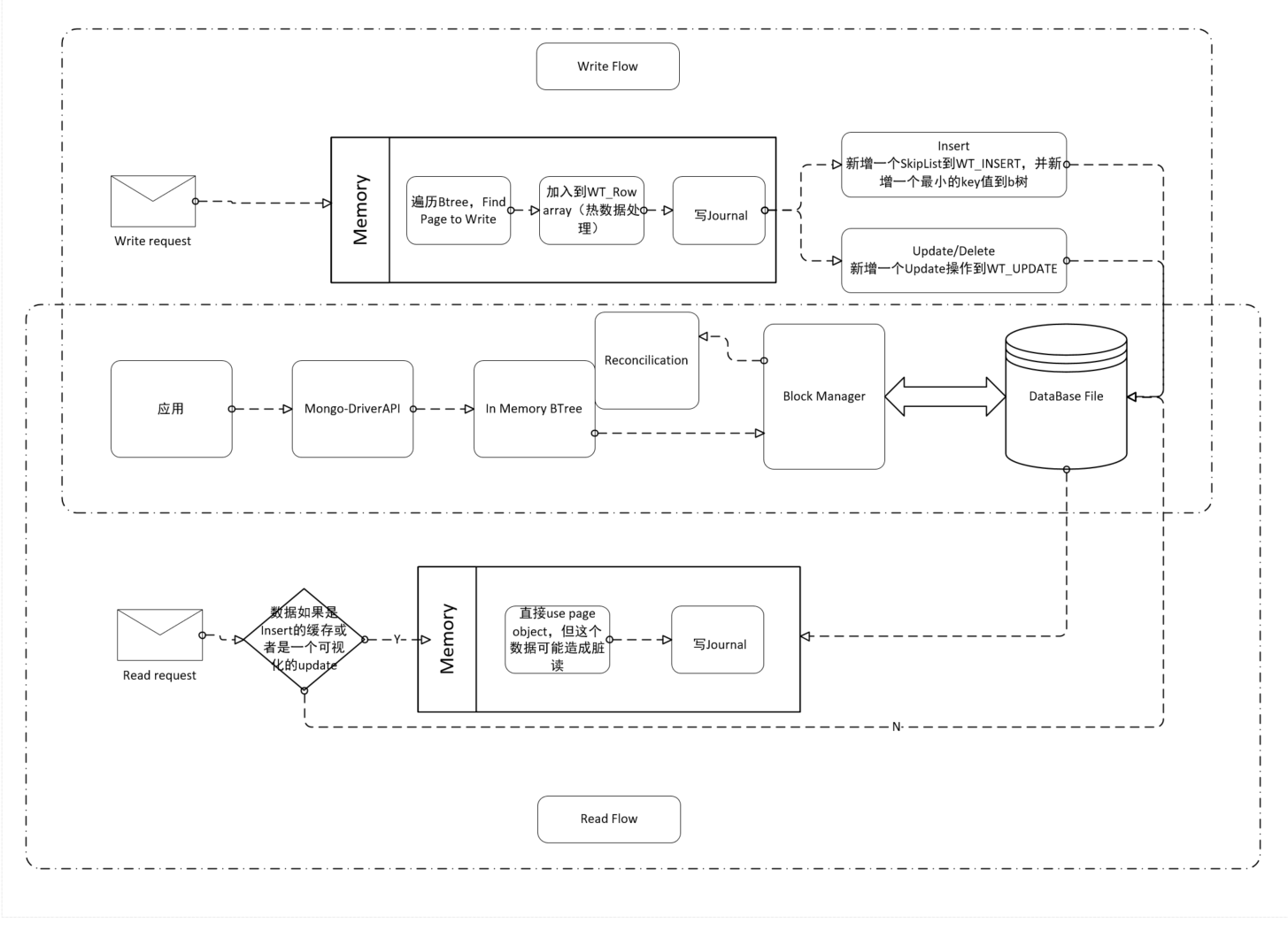
WriteFlow
- Traverse btree,find page to write
- InMem page if needed
- Construct WT_ROW array, one slot for each entry
- Write to page
- write journal if needed
- insert,One WT_INSERT skiplist for each entry,plus a speacial slot for keys smaller than any existed entry
- update/delete, one WT_UPATE for each entry
ReadFlow
- Traverse btree,find page to read
- InMem page if needed
- Construct WT_ROW array, one slot for each entry
- Read from page
- If there’s an insert object *If there’s a visible update:exact match
- Use the on page object (which may have an associated update object)
dirty数据的形成:
操作内存写入的最少单位是page,下图以page为单位展示,data是怎么变成used和dirty的。
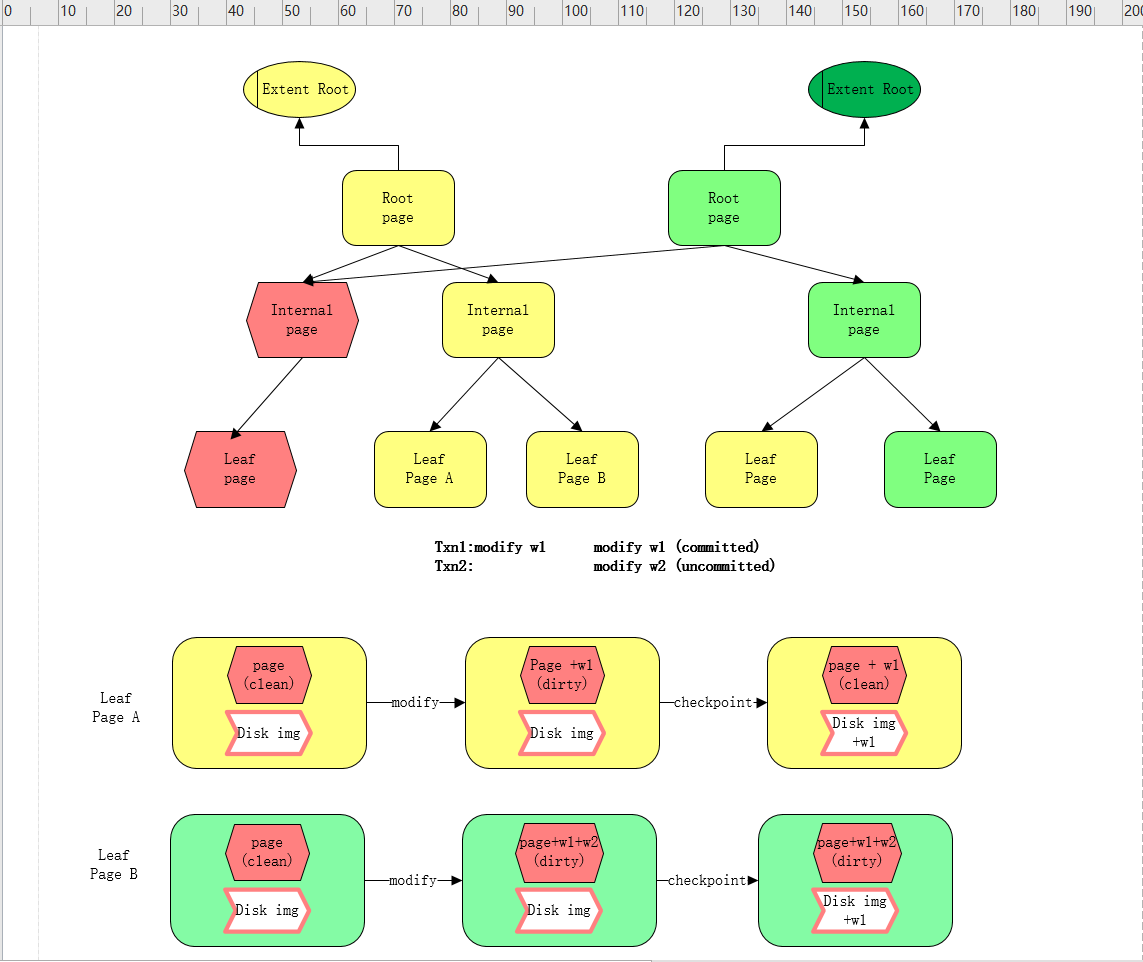
从上图可以看出数据变成dirty是以下两个方面的数据:
- 在checkpoint之前所有修改过的page数据都会标注为dirty
- 在checkpoint后,若此次刷盘的checkpoint存在uncommitted的数据那此次checkpoint的数据在缓存中就会被标注成dirty
数据分类清楚了之后,那到底mongo是怎么淘汰数据的呢
Eviction Cahce原理:
wiredtiger不例外的也是遵循了LRU原理来淘汰数据,过wiredtiger的eviction cache对数据页采用的是分段局部扫描和淘汰,而不是对内存中所有的数据页做全局管理。
具体evict的流程如下:
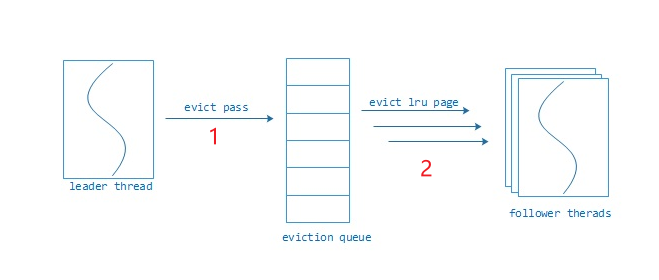
-
一个evict线程时间片内阶段性的去扫描各个btree,把满足淘汰条件的page添加到evictqueue中。
淘汰条件:
ü 如果page是数据页,必须page当前最新的修改事务必须早以evict pass事务。
ü 如果page是btree内部索引页,必须page当前最新的修改事务必须早以evict pass事务且当前处于evict queue中的索引页对象不多于10个。
ü 当前btree不处于正建立checkpoint状态
-
LRU评分排序阶段是在evict pass后进行的,当queue中有page时,会根据每个page当前的访问次数、page类型和淘汰失败次数等计算一个淘汰评分,然后按照评分从小打到进行快排,排序完成后,会根据queue中最大分数和最小分数计算一个淘汰边界evict_throld,queue中所有大于evict_throld的page不列为淘汰对象。
注: 对page的evict过程是个多线程协同操作过程,来加快淘汰处理,evict在设计的时候采用一种叫做leader-follower的线程模型,leader-follower通过抢锁来成为leader,具体采用的是hazard pointer无锁并发技术。
数据有了,淘汰机制有了,下面来谈如何优化
Eviction优化:
MongoDB 目前有4个可配置的参数来支持 wiredtiger 存储引擎的 eviction 策略调优,其含义是:
| 参数 | 默认值 | 含义 |
|---|---|---|
| eviction_target | 80 | 当 cache used 超过 eviction_target,后台evict线程开始淘汰 CLEAN PAGE |
| eviction_trigger | 95 | 当 cache used 超过 eviction_trigger,用户线程也开始淘汰 CLEAN PAGE |
| eviction_dirty_target | 5 | 当 cache dirty 超过 eviction_dirty_target,后台evict线程开始淘汰 DIRTY PAGE |
| eviction_dirty_trigger | 20 | 当 cache dirty 超过 eviction_dirty_trigger, 用户线程也开始淘汰 DIRTY PAGE |
如果上面的通过 mongostat和机器监控 发现 used、dirty 持续超出eviction_trigger、eviction_dirty_trigger,这时用户的请求线程也会去干 evict的事情(开销大),会导致请求延时上升,IO持续到达100%,这时基本可以判定,mongodb 已经存在资源不足的问题,即用户读写『从磁盘上写入的数据的速率』 远远 超出了 『mongodb 将数据从内存淘汰出去速率』
所以根据上述情况,其主要问题是机器IO撑爆,对于wiredTiger的调优策略为:
-
扩充机器内存,加大wiredTigerCache
ü 平衡写入数据与淘汰速率的差距
ü 增加dirty和used数据的容量大小,放缓大量数据写入,超限后的淘汰过程引起的高IO
-
eviction 参数调优
- 降低eviction_target与 eviction_dirty_target使得数据尽早刷盘
- 增大eviction_trigger与eviction_dirty_trigger使得用户线程减少参与evict
- 增大evict.threads_min(淘汰线程数)
3.存储引擎checkpoint优化調整
存储引擎得checkpoint检测點,实际上就是做快照,把当前存储引擎的脏数据全部记录到磁盘。触发checkpoint的条件默认又兩个,触发条件如下:
- 固定周期做一次checkpoint快照,默认60s
- 增量的redo log(也就是journal日志)达到2G
当journal日志达到2G或者redo log沒有达到2G並且距離上一次时间间隔达到60s,wiredtiger将会触发checkpoint,如果在兩次checkpoint的时间间隔evict淘汰线程淘汰的dirty page越少,那么积压的脏数据就会越多,也就是checkpoint的時候脏数据就會越多,造成checkpoint的时候大量的IO写盘操作。
如果我們把checkpoint的周期縮短,那麼兩个checkpoint期間的脏数据相应的也就會減少,磁盤IO 100%持续的时间也就會缩短。
checkpoint調整後的值如下:
checkpoint=(wait=25,log_size=1GB)
WiredTiger优化后磁盘IO:
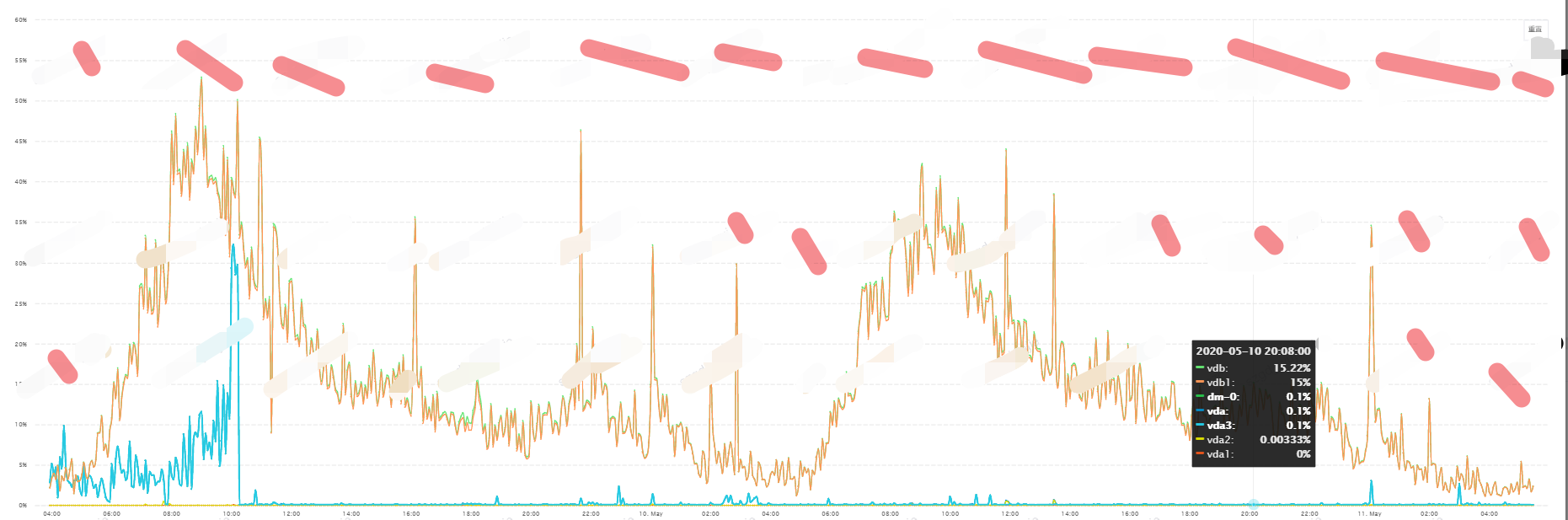
從上图可以看出,存储引擎优化后IO由高企100%缓解到50%以下,时间延迟进一步降低並处于平穩,從平均80ms到平均20ms左右。
非运维人员,简单程序员,所以进一步对于机器和数据库的专业优化还需指点。但暂时mongo此次优化效果满意,写下此篇。助日后思考理解。